Seeds of Creativity
Generative AI models have sparked a debate over the nature of creativity and the extent to which machines are capable of it. With AI models that can generate novel images, stories, and other creative works, what truly counts as human creativity? Are we, also, just predicting the next words when we speak? Or is there something more to it?
We should expect to see continued improvements even with current approaches to model development, so we won't see this issue go away any time soon. However, when we talk about creativity, we often mean different things. Is generating an image of a person that wasn't specifically in the training set creative? Or, perhaps, a dog playing chess?
It's best to think about different poles of creativity. Instead of categories, inside of which every creative work exists, these are different axes along which creativity may vary:
- Content reproduction. We reproduce variants of what already exists.
- Semantic reproduction. We create different content but similar semantics as what we've seen.
- Synthesis. We combine concepts from different pieces or genres, interpolating between what exists but potentially producing something novel or unusual.
- Domain-expansion. We expand what can be created by establishing entirely new ideas that aren't simply based on synthesizing existing knowledge.
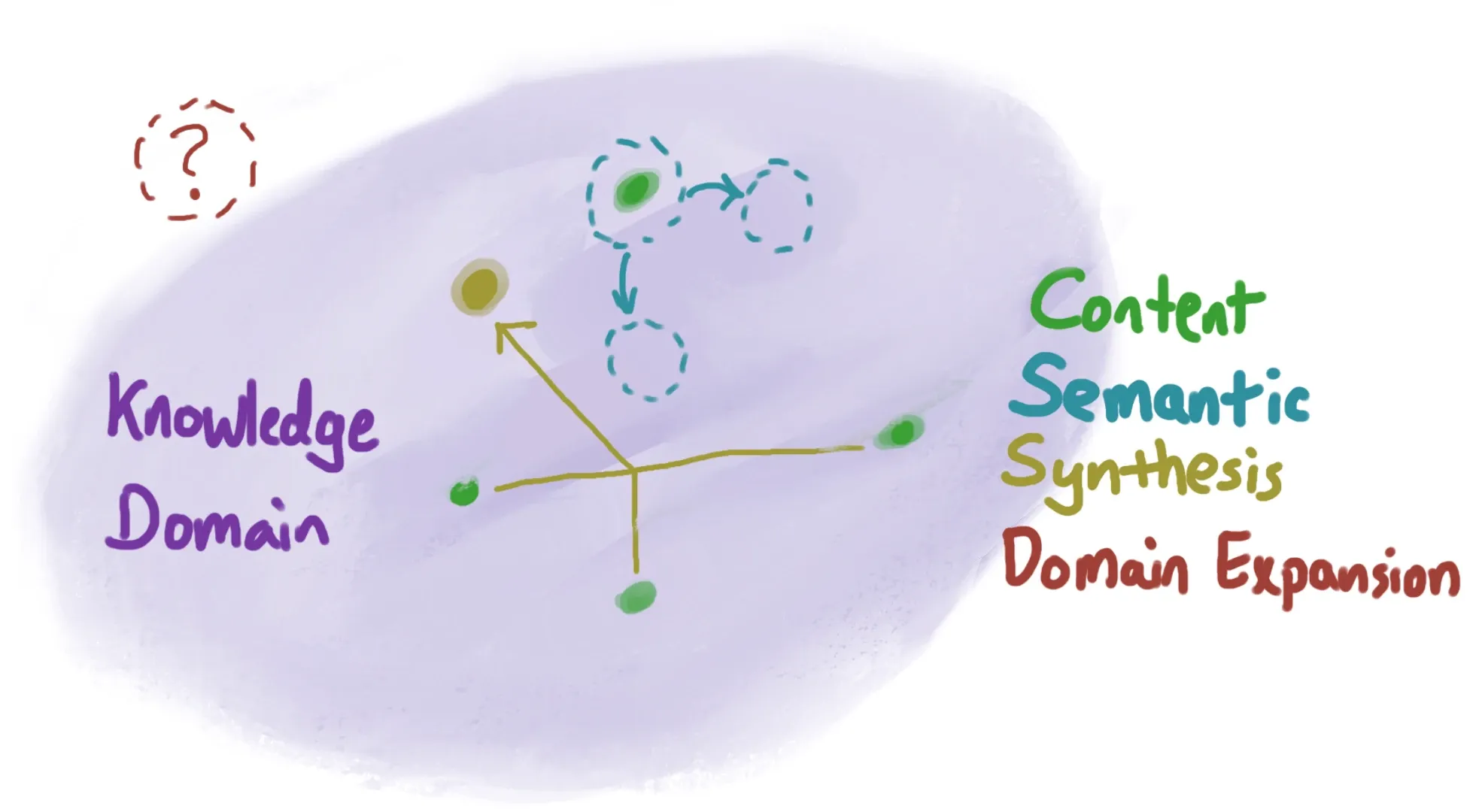
When people say that Stable Diffusion is just reproducing what it was trained on—literally copying training data—they're largely talking about content and semantic reproduction (see the Getty lawsuit).
But, clearly, these models can synthesize between concepts. This is what's happening when GPT writes a sonnet about Elon Musk riding a rocket to Mars. This wasn't in the training corpus directly, but, in another sense, was — the form of sonnets and content about Elon Musk. Many models are specifically designed to not directly reproduce trained content, to generalize on many semantic meanings ("dog", "Elon Musk", "playing chess"), and ideally be able to synthesize between concepts ("a dog playing chess"). We might estimate that the current Stable Diffusion model has these rough qualities (ignoring domain-expansion for now):
{kind=link}
- 1/5 Content reproduction, as it's specifically been trained to minimize this
- 5/5 Semantic reproduction, as it generalizes concepts well
- 3/5 Synthesis, as it is able to combine many concepts, but fails with some
Note that this outcome isn't necessarily a limitation of AI models in general; it's just describing how one specific model, trained one specific way seems to behave. (Since these models keep getting better, assume the values are relative; later this year, we may be blown away about how much better the synthesis is, for example.)
AI is already more creative than we are
With the release of Midjourney v5 and GPT-4, we're reminded an important lesson: nearly all human "creativity" is content reproduction and synthesis (see Everything is a Remix). So seeing these done so well by AI has been surprising to many of us. When we train models to be believable and produce appealing content, what comes out is... believable and appealing. GPT-4 is already capable of astounding synthesis of ideas. As it turns out, while expanding the knowledge domain feels still "owned" by humans, the landscape between existing knowledge is massively under-explored.
We should expect to see discoveries to be made by AI, including in creative domains such as drug research, mathematical proof, and synthetic biology. Not because AI has become super-intelligent, whatever that means, but because it can synthesize between existing knowledge faster, and sometimes better, than we can.
There's one issue, though: current generation machine learning models have no reference to reality. Their output just exists, and needs to be evaluated by humans to become meaningful. I'm making a subtle argument here, so I'll tread carefully. Brute forcing every music melody will definitionally contain incredibly beautiful and sublime music, but the brute forcing process has no idea which melodies are good. Likewise, Midjourney can produce beautiful images, but has no concept of what is good — many of its outputs are good because we train it on things we like, but it has no ability to keep getting better by itself, because it doesn't know what better means. When we train ML models to play games, there is a clear objective function so that "better" is clear and can be optimized, but this is not generally true. GPT-4 may be capable of text output that solves our current centralized monetary policy issues, but is also capable of plenty of nonsense. It's only when we can "evaluate" these outputs against reality—which includes our aesthetic tastes, our preferences, etc—that meaning comes from them.
This is why these models need real human-generated data to learn. They can't be trained generatively, because they need objectives. For language models, it's predicting the next token. For diffusion models, it's reducing noise to get closer to "real" images. Given more data without information content, they cannot get better.
What might be unique to human creativity?
From an outside view, since humans do indeed expand our knowledge domain, we must do all four of the above. AIs do at least the first three. The last kind of creativity—knowledge domain expansion—is more nebulous, and potentially exceedingly rare. We don't have a known mechanism of how LLMs would approach this, and finding evidence of this is quite difficult. For specific examples, something that looks like domain-expansion could just be content or semantic synthesis. Could it happen? Perhaps, but there is a core difference for how humans might do this and how LLMs are currently designed: objective functions and accountability to reality.
I want to be clear: domain-expansion is hard for humans, and what looks entirely novel is often a derivative of what came before. In fact, I can't think of any "truly novel" innovation that didn't have a component of semantic interpolation. So, we need to tread carefully, and recognize that exclusive domain-expansion may not exist.
“You insist that there is something a machine cannot do. If you tell me precisely what it is a machine cannot do, then I can always make a machine which will do just that.”
– John von Neumann
Here's the closest I can get to how humans expand our knowledge domain:
- We learn a lot about the world. It's difficult to be creative if you haven't been exposed to a lot. Knowing about many disciplines is better.
- Analogies emerge that capture various essences. These aren't pre-existing categories; we're not forming platonic ideals.
- We make leaps outside of the existing knowledge domain by porting analogies to new contexts, with an influence of happy accidents, mistakes, and noise.
- New concepts are then evaluated against a grounding in reality. If they're grounded, they establish new areas of knowledge.
There's a lot to unpack here. When I talk about knowledge, this applies to artistic domains as well — artistic knowledge relates to resonance with beauty, interestingness, insight, etc. So, in this sense, learning is both about facts, but also a resonance that is in a relational context with the world. Fundamentally, we're building abstractions and analogies, and to do so effectively, require a feedback loop. Transformer language models approximate this differently: their feedback loop is predicting the next token from human-written text, and iteratively decreasing how much they're wrong (gradient descent).
Analogies are not categories. They're nebulous, yet patterned. A mug holding pencils has less proximity to "cup-ness" than if it held tea, and hands dipped into a river to get water gain "cup-ness". "Cup" is just a pointer to a nebulous but real area of understanding, and can evolve and change over time and in new contexts. This is a deep and nuanced insight that Douglas Hofstadter has spent years cultivating that I won't do justice, but we'll visit one example to develop the concept further:
A shadow is a dark area where light is blocked by another object. But there's other shadows, if we can extend the analogy a bit. If snow falls in late autumn on a tree, especially if there are still leaves, the snow may be shielded from under the tree — creating a snow shadow. We could borrow the concept further: throwing shade, describing an insult specifically cast upon someone, often non-verbal, with no wider impact beyond the intended target.
(If you're interested in this delightful rabbit hole, I highly recommend Hofstadter's lecture Analogy as the Core of Cognition and his book with Emmanuel Sander, Surfaces and Essences.)
Analogies allow us to port patterns to entirely new areas. Sometimes this is just semantic synthesis, but occasionally it is lands firmly outside of the existing knowledge domain. Additionally, practical human cognition affords many opportunities for happy accidents — mistakes or flukes that weren't directed towards intentionally. When this occurs, we don't always know where we landed. Is this interesting? true? resonate with reality?
This is where the objective comes in. Reality has no objective function (what's being optimized). With our own creative and scientific pursuits, instead, we're accountability to reality. These are fundamentally different. What does this look like in practice?
In art, it's often about resonance with self expression and with others. Pure self expression is memetic only to the extent that it also resonates with others, potentially not even as the artist intended. In science, through a process of theory development—looking for internal inconsistencies, prediction of existing known phenomena, and often beauty—and experiment, we validate our new hypotheses.
So, we combine generalized analogies, semantic synthesis, and randomness, and "worm hole" into a new place. We then look around evaluate that place. Many things aren't true, or fail to be useful. Many experiments, artistic and scientific, fail. But occasionally, we discover something truly novel that is useful, in a way that expands our knowledge domain. Once this happens, all the other more simple modes of creativity kick in. People can quickly connect the new region of knowledge to existing regions through synthesis, and potentially port new analogies to new domains.
Because of this, knowledge domain-expanding creativity is uncommon, surprising, and random. It cannot be planned, it happens as curious minds have capacity and freedom to explore.
The myth of the objective
We now have a model for how humans approach novel creativity. What might an AI do to have the same outcome?
I'm now realizing that many folks assume there must be somebody on earth who knows how LLMs work. This is false. Nobody knows how they work or how to program one. We know how to find LLMs using SGD, but that doesn't tell us anything about how they work or about how to program one
— Ronny Fernandez 🔍 (@RatOrthodox) December 19, 2022
Current generation models may have the ability to analogize, though it's not clear to me whether it's the same as how we do it, and not entirely clear how we do it! It may be similar, or be approximately similar enough. I suspect, though, that their form of analogies are closer to dynamic and emergent categories, learned through statistical relationships in the training data. (Could current ML models create terms like "throwing shade", after understanding shadows? Unclear, but I'd be interested in examples that may illustrate whether this can happen one way or another.)
However, ML models can, most definitely, interface with randomness — factories for happy accidents. In fact, most production models have configurable settings at evaluation time called temperature that introduces some noise in the output. Currently, this is limited to evaluation of the models. During training, the loss function is the objective. And we're not yet good at designing great loss functions. It's shocking to me that predicting the next token, iteratively, produces such rich behavior from language models — yet this objective is still quite simple.
Whatever analogizing the models are capable of, combined with run-time randomness, may indeed produce output firmly outside of the existing knowledge domain. However, so can any random process, like a chimpanzee on typewriter. If Stable Diffusion produces random noise, few people would leap to the conclusion that it's being "creative", even if the output is firmly outside our existing domain of knowledge. So what matters here, to have useful domain-expansion creativity, is an accountability to reality.
Humans are directly accountable to reality. If you have an idea, you can consult reality (observation, feedback from others, hypothesis testing, etc) for feedback. Yet, reality is an exceedingly complex and nebulous environment that provides no clean, differentiable objective function.
Both language models like GPT and image diffusion models like Stable Diffusion directly attempt to steer towards least-surprise. For text, we want to predict the most statistically likely next token. For images, we want to remove noise iteratively. This "grounding function" will always send us back to what they were trained on, or at least areas between training data. Modifying this process to explore beyond what they were trained on has no anchor that helps them evaluate whether it's good or right.
For this reason, I'm doubtful that current generation generative models exhibit anything close to knowledge domain-expanding creativity. They have no reference to reality. We may see (or have already seen) super-human abilities to synthesize knowledge between different domains, just as a calculator can perform super-human mathematical calculation.
We can and will continue to see "creativity" in tightly-controlled domains. For example, AlphaGo's 37th move is regarded as non-human and creative. But that's our interpretation, based on how humans play Go. As it turns out, machines—with a well-defined objective to win the game—play Go slightly differently. And thus, we can learn from them and improve our own games.
The debate whether these models are "creative" ends up being a debate about semantics and definitions. Most of human creativity is synthesis, so in unconstrained domains like language models and image diffusion, what these models do is both exciting and surprising. But we have no current ways of building accountability to reality.
Will we have one? I'm doubtful — reality has a surprising amount of detail, and what we need is meta-rationality. In fact, AI may grow in sophistication in ways that are unlike how we measure intelligence in humans, exploiting their ability to search vast information and perform discrete calculations better than we can.
In the next few years, we'll see models being able to directly access structured databases, to both ensure we control what they "know", and to make updating/re-training cheaper. This will give us more explainability of models, and potentially massively increase their accuracy.
We may also see models that dynamically and constantly update based on ongoing feedback. The models may not be able to evaluate an objective function of reality, but can update based on feedback from people. In fact, that's what ChatGPT used during training. I assume that marrying training and evaluation will happen soon enough, with human feedback updating models far more dynamically. In a weird way, people may become the evaluators that the models "rely on" to approximate reality more and more.

Special thanks to David Chapman for the concept of accountability to reasonableness and objectives, and Douglas Hofstaedter's ideas about cognition. I'm merely synthesizing their great work. Thanks to Jake Orthwein and Noah Maier for editorial feedback.